ConcurrentLinkedQueue
ConcurrentLinkedQueue的结构
通过ConcurrentLinkedQueue的类图来分析一下它的结构,如下: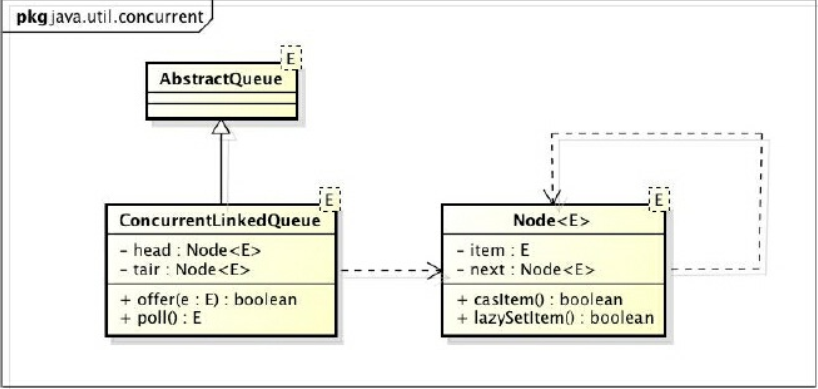
ConcurrentLinkedQueue由head节点和tail节点组成,每个节点(Node)由节点元素(item)和指向下一个节点(next)的引用组成,节点与节点之间就是通过这个next关联起来,从而组成一张链表结构的队列.默认情况下head节点存储的元素为空,tail节点等于head节点
1 | head = tail = new Node<E>(null) |
入队列
入队列的过程
入队列就是将入队节点添加到队列的尾部.为了方便理解入队时队列的变化,以及head节点和tail节点的变化,这里以一个示例来展开介绍.假设我们想在一个队列中依次插入4个节点,为了帮助大家理解,每添加一个节点就做了一个队列的快照图,如下图所示: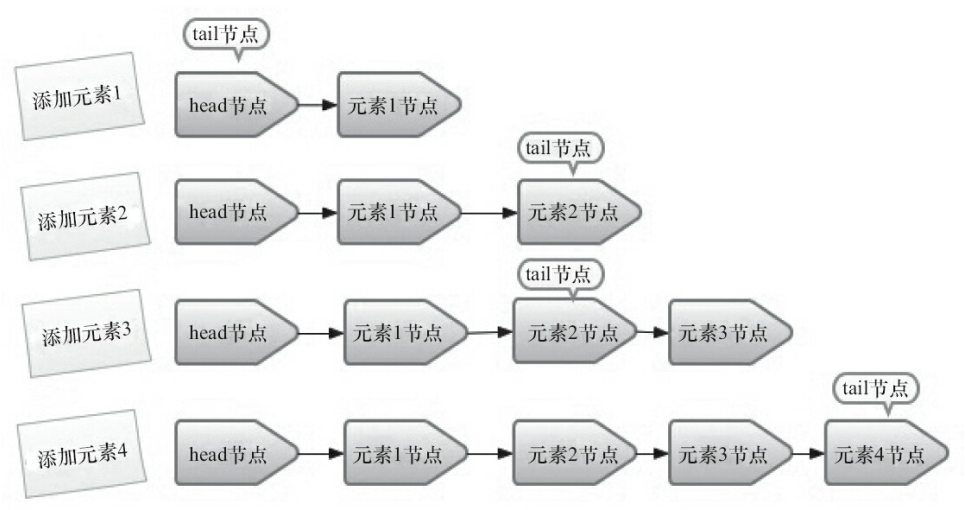
- 添加元素1:队列更新head节点的next节点为元素1节点.又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点
- 添加元素2: 队列首先设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点
- 添加元素3:设置tail节点的next节点为元素3节点
- 添加元素4:设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点
通过调试入队过程并观察head节点和tail节点的变化,发现入队主要做两件事情:
- 将入队节点设置成当前队列尾节点的下一个节点
- 更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点
通过对上面的分析,我们从单线程入队的角度理解了入队过程,但是多个线程同时进行入队的情况就变得更加复杂了,因为可能会出现其他线程插队的情况.如果有一个线程正在入队,那么它必须先获取尾节点,然后设置尾节点的下一个节点为入队节点,但这时可能有另外一个线程插队了,那么队列的尾节点就会发生变化,这时当前线程要暂停入队操作,然后重新获取尾节点.让我们再通过源码来详细分析一下它是如何使用CAS算法来入队的
1 | public boolean offer(E e) { |
从源代码角度来看,整个入队过程主要做两件事情:第一是定位出尾节点;第二是使用CAS算法将入队节点设置成尾节点的next节点,如不成功则重试
定位尾节点
tail节点并不总是尾节点,所以每次入队都必须先通过tail节点来找到尾节点.尾节点可能是tail节点,也可能是tail节点的next节点.代码中循环体中的第一个if就是判断tail是否有next节点,有则表示next节点可能是尾节点.获取tail节点的next节点需要注意的是p节点等于p的next节点的情况,只有一种可能就是p节点和p的next节点都等于空,表示这个队列刚初始化,正准备添加节点,所以需要返回head节点,获取p节点的next节点代码如下
1 | final Node<E> succ(Node<E> p) { |
设置入队节点为尾节点
p.casNext(null,n)方法用于将入队节点设置为当前队列尾节点的next节点,如果p是null,表示p是当前队列的尾节点,如果不为null,表示有其他线程更新了尾节点,则需要重新获取当前队列的尾节点
HOPS的设计意图
出队列
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用.让我们通过每个节点出队的快照来观察一下head节点的变化,如下图: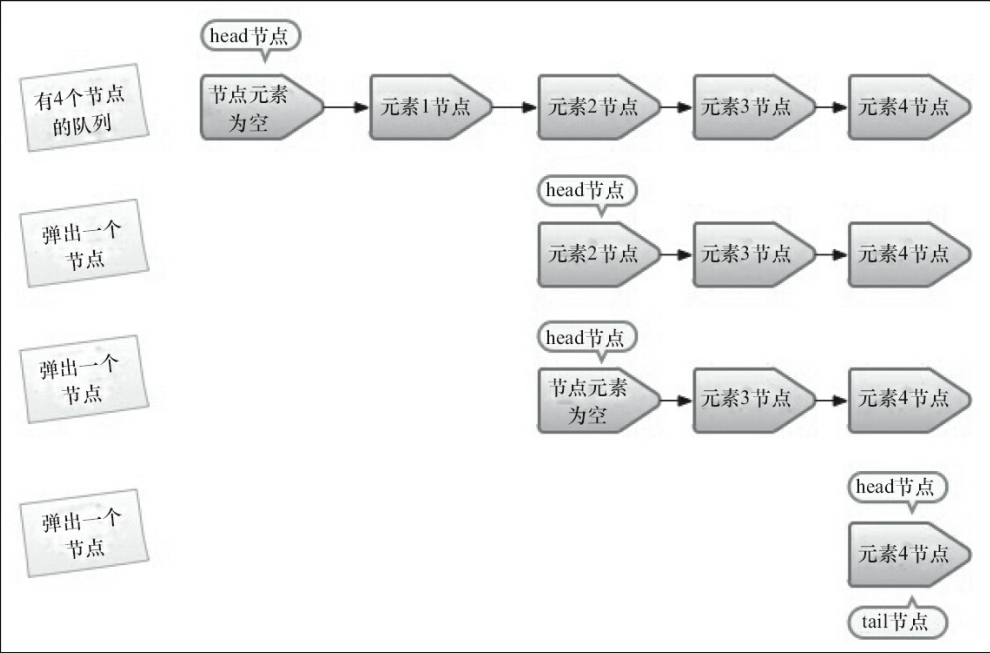
从图中可知,并不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点.只有当head节点里没有元素时,出队操作才会更新head节点.这种做法也是通过hops变量来减少使用CAS更新head节点的消耗,从而提高出队效率.让我们再通过源码来深入分析下出队过程
1 | public E poll() { |
首先获取头节点的元素,然后判断头节点元素是否为空,如果为空,表示另外一个线程已经进行了一次出队操作将该节点的元素取走,如果不为空,则使用CAS的方式将头节点的引用设置成null,如果CAS成功,则直接返回头节点的元素,如果不成功,表示另外一个线程已经进行了一次出队操作更新了head节点,导致元素发生了变化,需要重新获取头节点







