happens-before规则
happens-before是JMM最核心的概念.对应Java程序员来说,理解happens-before是理解JMM的关键
JMM的设计
程序员对内存模型的使用.程序员希望内存模型易于理解、易于编程.程序员希望基于一个强内存模型来编写代码
编译器和处理器对内存模型的实现.编译器和处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能.编译器和处理器希望实现一个弱内存模型
JSR-133专家组在设计JMM时的核心目标就是找到一个好的平衡点:
1 | double pi = 3.14; // A |
上面计算圆的面积的示例代码存在3个happens-before关系,如下:
- A happens-before B
- B happens-before C
- A happens-before C
在3个happens-before关系中,2和3是必需的,但1是不必要的.因此,JMM把happens-before要求禁止的重排序分为了下面两类:
- 会改变程序执行结果的重排序
- 不会改变程序执行结果的重排序
JMM对这两种不同性质的重排序,采取了不同的策略,如下:
- 对于会改变程序执行结果的重排序,JMM要求编译器和处理器必须禁止这种重排序
- 对于不会改变程序执行结果的重排序,JMM对编译器和处理器不做要求(JMM允许这种重排序)
JMM的设计示意图: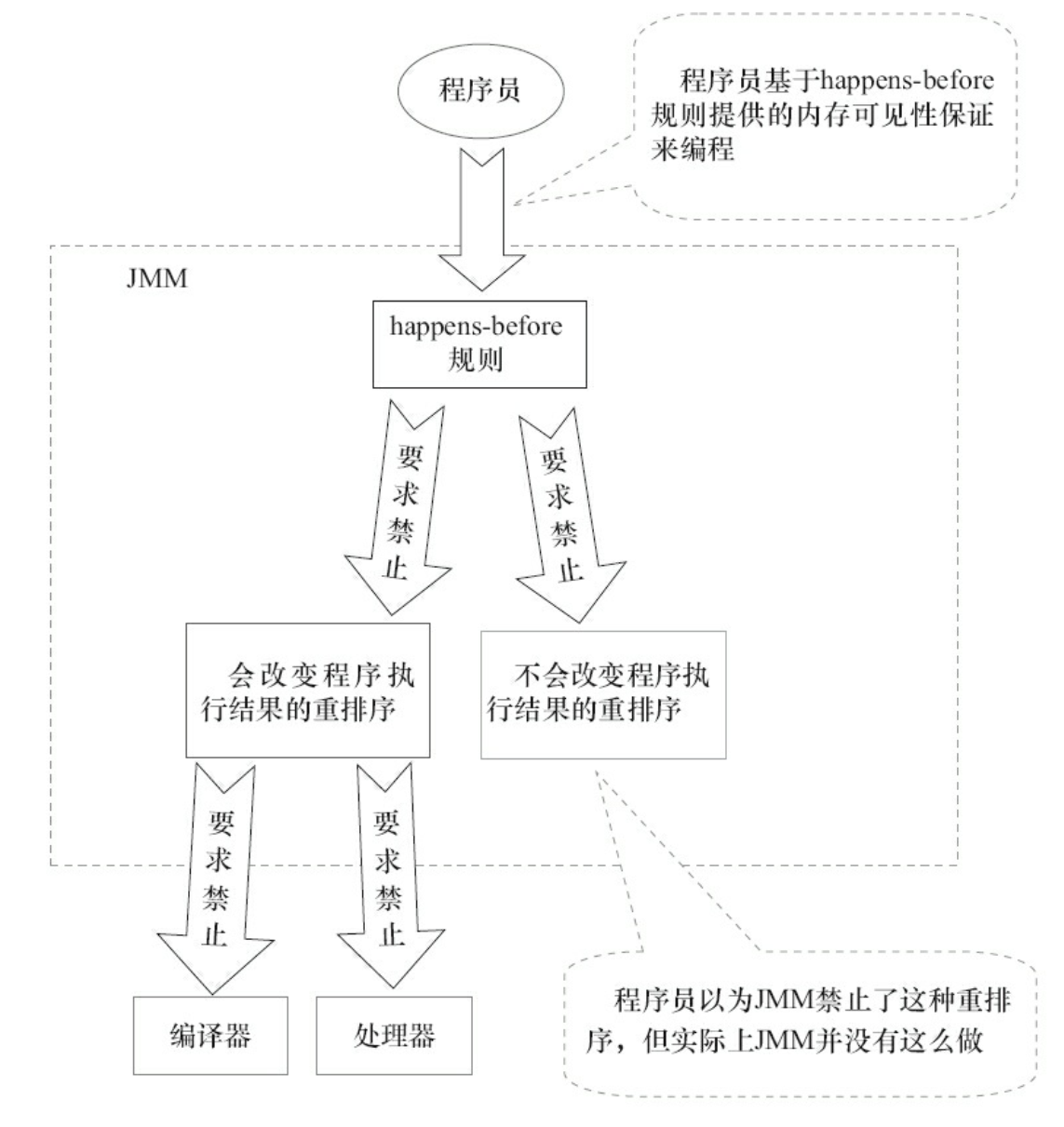
从上可以看出以下两点:
- JMM向程序员提供的happens-before规则能满足程序员的需求.JMM的happens-before规则不但简单易懂,而且也向程序员提供了足够强的内存可见性保证(有些内存可见性保证其实并不一定真实存在,比如上面的A happens-before B)
- JMM对编译器和处理器的束缚已经尽可能少.从上面的分析可以看出,JMM其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行.例如,如果编译器经过细致的分析后,认定一个锁只会被单个线程访问,那么这个锁可以被消除.再如,如果编译器经过细致的分析后,认定一个volatile变量只会被单个线程访问,那么编译器可以把这个volatile变量当作一个普通变量来对待.这些优化既不会改变程序的执行结果,又能提高程序的执行效率
happens-before的定义
happens-before关系的定义如下:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行.如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)
1是JMM对程序员的承诺.从程序员的角度来说,可以这样理解happens-before关系:如果A happens-before B,那么Java内存模型将向程序员保证——A操作的结果将对B可见,且A的执行顺序排在B之前.注意,这只是Java内存模型向程序员做出的保证
2是JMM对编译器和处理器重排序的约束原则.正如前面所言,JMM其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行.JMM这么做的原因是:程序员对于这两个操作是否真的被重排序并不关心,程序员关心的是程序执行时的语义不能被改变(即执行结果不能被改变).因此,happens-before关系本质上和as-if-serial语义是一回事
- as-if-serial语义保证单线程内程序的执行结果不被改变,happens-before关系保证正确同步的多线程程序的执行结果不被改变
- as-if-serial语义给编写单线程程序的程序员创造了一个幻境:单线程程序是按程序的顺序来执行的.happens-before关系给编写正确同步的多线程程序的程序员创造了一个幻境:正确同步的多线程程序是按happens-before指定的顺序来执行的
as-if-serial语义和happens-before这么做的目的,都是为了在不改变程序执行结果的前提下,尽可能地提高程序执行的并行度
happens-before规则
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C
- start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的
ThreadB.start()操作happens-before于线程B中的任意操作 - join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回
双重检查锁定与延迟初始化
双重检查锁定来实现延迟初始化的示例代码
1 | public class DoubleCheckedLocking { // 1 |
如上面代码所示,如果第一次检查instance不为null,那么就不需要执行下面的加锁和初始化操作.因此,可以大幅降低synchronized带来的性能开销.
- 多个线程试图在同一时间创建对象时,会通过加锁来保证只有一个线程能创建对象
- 在对象创建好之后,执行getInstance()方法将不需要获取锁,直接返回已创建好的对象
双重检查锁定看起来似乎很完美,但这是一个错误的优化!在线程执行到第4行,代码读取到instance不为null时,instance引用的对象有可能还没有完成初始化
问题的根源
前面的双重检查锁定示例代码的第7行(instance=new Singleton();)创建了一个对象.这一行代码可以分解为如下的3行伪代码
1 | memory = allocate(); // 1:分配对象的内存空间 |
上面3行伪代码中的2和3之间,可能会被重排序,2和3之间重排序之后的执行时序如下
1 | memory = allocate(); // 1:分配对象的内存空间 |
下面我们查看多线程并发执行的情况: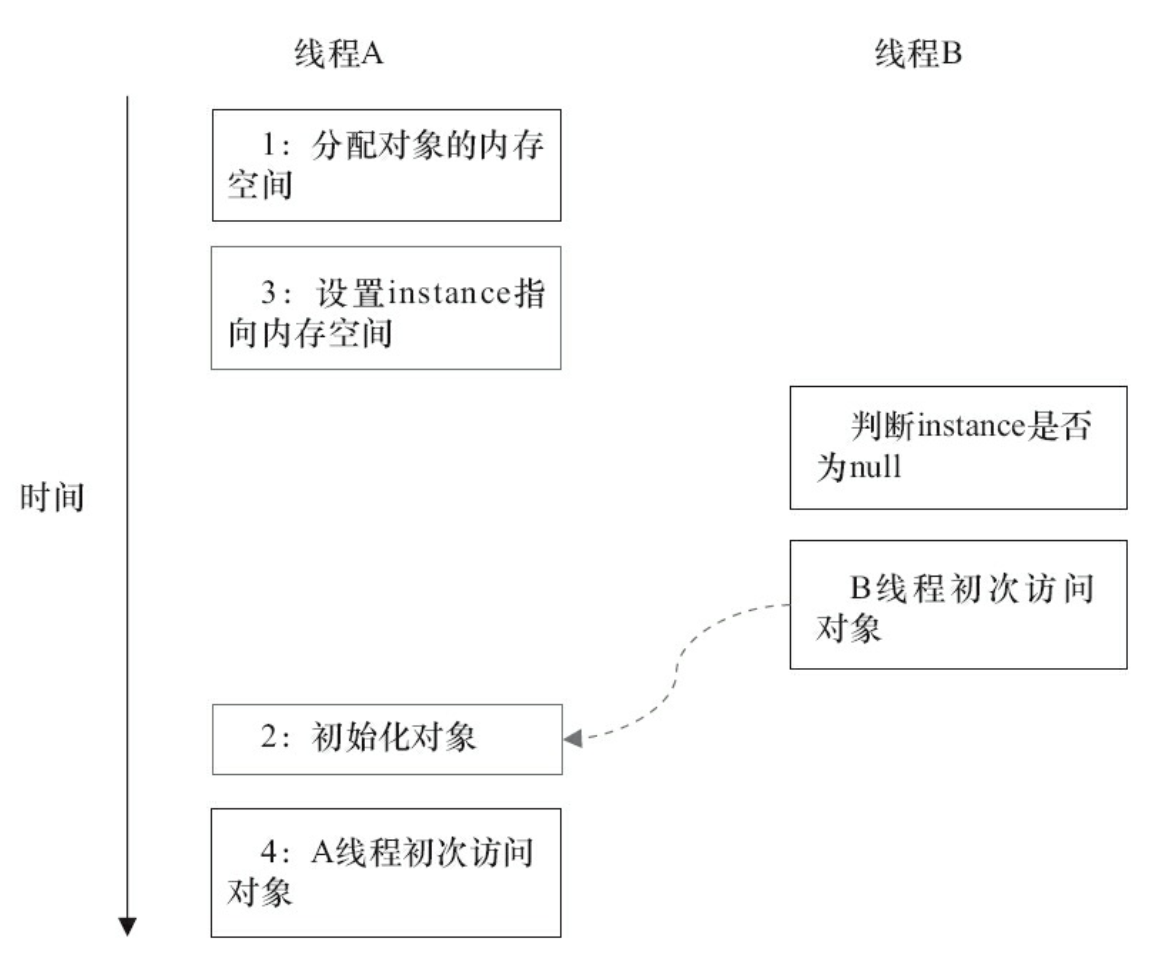
由于单线程内要遵守intra-thread semantics,从而能保证A线程的执行结果不会被改变.但是,当线程A和B按上图的时序执行时,B线程将看到一个还没有被初始化的对象
DoubleCheckedLocking示例代码的第7行(instance=new Singleton();)如果发生重排序,另一个并发执行的线程B就有可能在第4行判断instance不为null.线程B接下来将访问instance所引用的对象,但此时这个对象可能还没有被A线程初始化!
| 时间 | 线程A | 线程B |
|---|---|---|
| t1 | A1: 分配对象的内存空间 | |
| t2 | A3:设置instance指向内存空间 | |
| t3 | B1:判断instance是否为空 | |
| t4 | B2:由于instance不为null,线程B将访问instance引用的对象 | |
| t5 | A2:初始化对象 | |
| t6 | A4:访问instance引用的对象 |
这里A2和A3虽然重排序了,但Java内存模型的intra-thread semantics将确保A2一定会排在A4前面执行.因此,线程A的intra-thread semantics没有改变,但A2和A3的重排序,将导致线程B在B1处判断出instance不为空,线程B接下来将访问instance引用的对象.此时,线程B将会访问到一个还未初始化的对象
在知晓了问题发生的根源之后,我们可以想出两个办法来实现线程安全的延迟初始化:
- 不允许2和3重排序
- 允许2和3重排序,但不允许其他线程”看到”这个重排序
基于volatile的解决方案
对于前面的基于双重检查锁定来实现延迟初始化的方案(指DoubleCheckedLocking示例代码),只需要做一点小的修改(把instance声明为volatile型),就可以实现线程安全的延迟初始化.请看下面的示例代码
1 | public class SafeDoubleCheckedLocking { |
这个解决方案需要JDK 5或更高版本(因为从JDK 5开始使用新的JSR-133内存模
型规范,这个规范增强了volatile的语义)
当声明对象的引用为volatile后,3行伪代码中的2和3之间的重排序,在多线程环境中将会被禁止,上面示例代码将按如下的时序执行,如下图所示: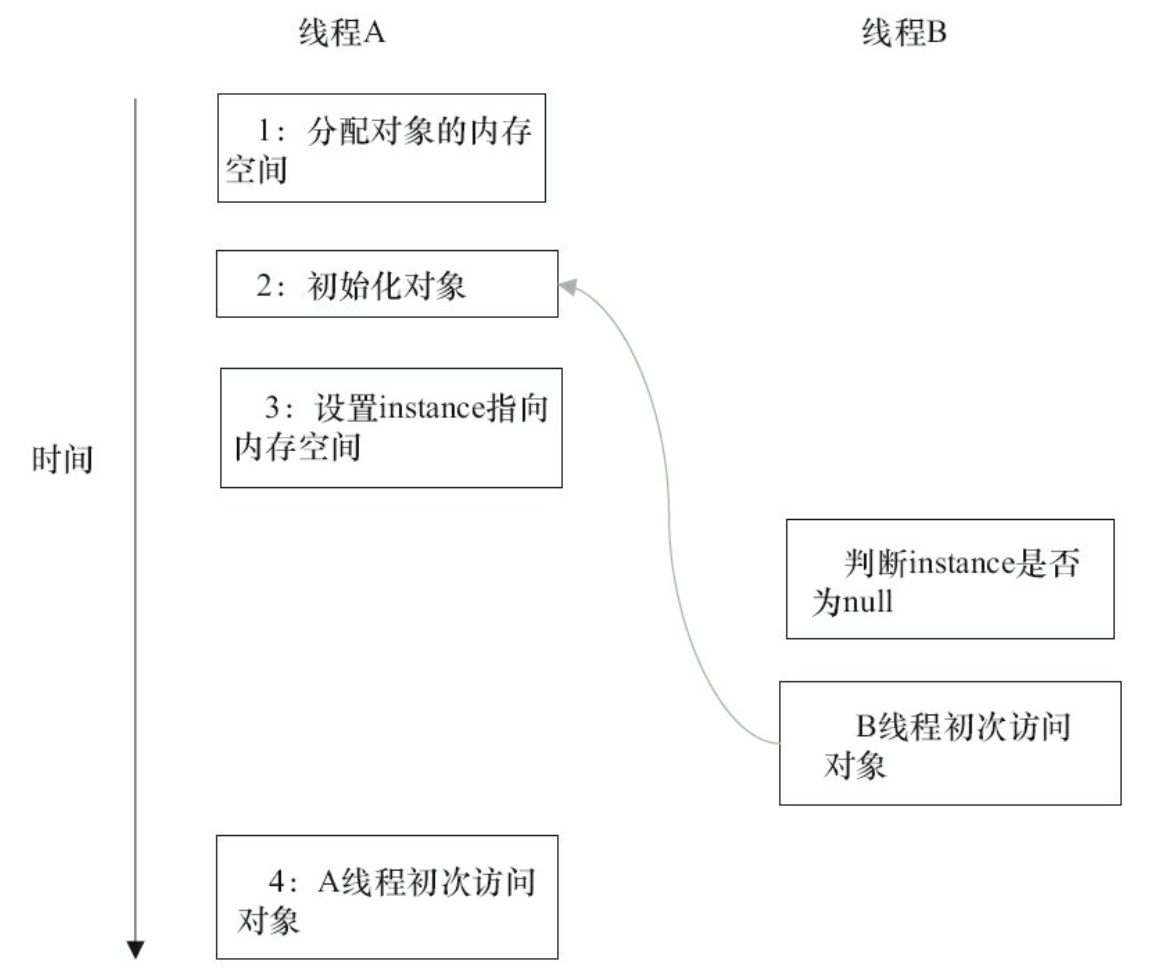
这个方案本质上是通过禁止2和3之间的重排序,来保证线程安全的延迟初始化
基于类初始化的解决方案
JVM在类的初始化阶段(即在Class被加载后,且被线程使用之前),会执行类的初始化.在执行类的初始化期间,JVM会去获取一个锁.这个锁可以同步多个线程对同一个类的初始化
基于这个特性,可以实现另一种线程安全的延迟初始化方案(这个方案被称之为Initialization On Demand Holder idiom)
1 | public class InstanceFactory { |
假设两个线程并发执行getInstance()方法,下面是执行的示意图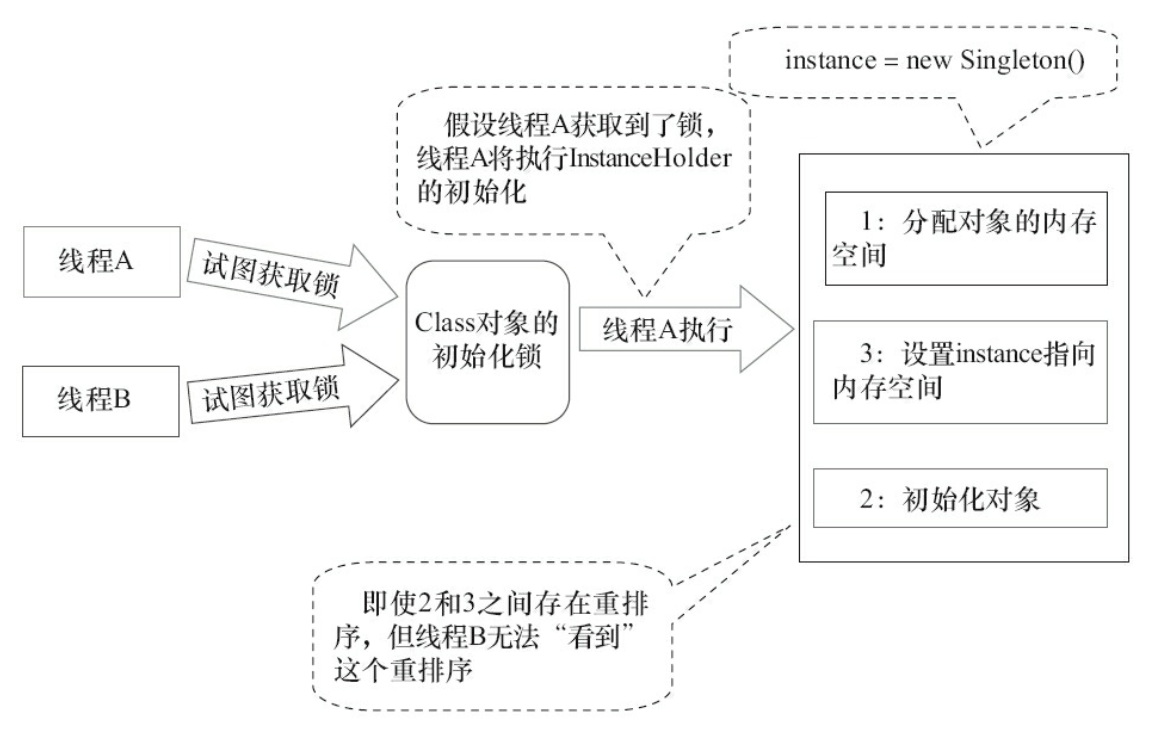
这个方案的实质是:允许3行伪代码中的2和3重排序,但不允许非构造线程(这里指线程B)”看到”这个重排序
初始化一个类,包括执行这个类的静态初始化和初始化在这个类中声明的静态字段.根据Java语言规范,在首次发生下列任意一种情况时,一个类或接口类型T将被立即初始化
- T是一个类,而且一个T类型的实例被创建
- T是一个类,且T中声明的一个静态方法被调用
- T中声明的一个静态字段被赋值
- T中声明的一个静态字段被使用,而且这个字段不是一个常量字段
- T是一个顶级类(Top Level Class,见Java语言规范的§7.6),而且一个断言语句嵌套在T内部被执行
在InstanceFactory示例代码中,首次执行getInstance()方法的线程将导致InstanceHolder类被初始化
由于Java语言是多线程的,多个线程可能在同一时间尝试去初始化同一个类或接口(比如这里多个线程可能在同一时刻调用getInstance()方法来初始化InstanceHolder类).因此,在Java中初始化一个类或者接口时,需要做细致的同步处理
对于类或接口的初始化,Java语言规范制定了精巧而复杂的类初始化处理过程.Java初始化一个类或接口的处理过程如下:
- 第1阶段:通过在Class对象上同步(即获取Class对象的初始化锁),来控制类或接口的初始化.这个获取锁的线程会一直等待,直到当前线程能够获取到这个初始化锁
- 第2阶段:线程A执行类的初始化,同时线程B在初始化锁对应的condition上等待
- 第3阶段:线程A设置state=initialized,然后唤醒在condition中等待的所有线程
- 第4阶段:线程B结束类的初始化处理
总结
通过对比基于volatile的双重检查锁定的方案和基于类初始化的方案,我们会发现基于类初始化的方案的实现代码更简洁.但基于volatile的双重检查锁定的方案有一个额外的优势:除了可以对静态字段实现延迟初始化外,还可以对实例字段实现延迟初始化
字段延迟初始化降低了初始化类或创建实例的开销,但增加了访问被延迟初始化的字段的开销.在大多数时候,正常的初始化要优于延迟初始化.如果确实需要对实例字段使用线程安全的延迟初始化,请使用上面介绍的基于volatile的延迟初始化的方案;如果确实需要对静态字段使用线程安全的延迟初始化,请使用上面介绍的基于类初始化的方案







