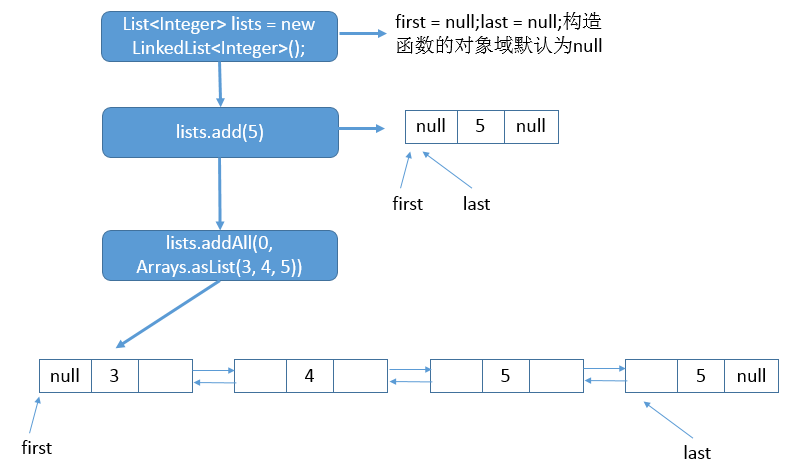
/** * 通过一个集合初始化LinkedList,元素的顺序由集合的迭代器返回顺序决定 * @param c the collection whose elements are to be placed into this list * @throws NullPointerException if the specified collection is null */ publicLinkedList(Collection<? extends E> c){ this(); addAll(c); }
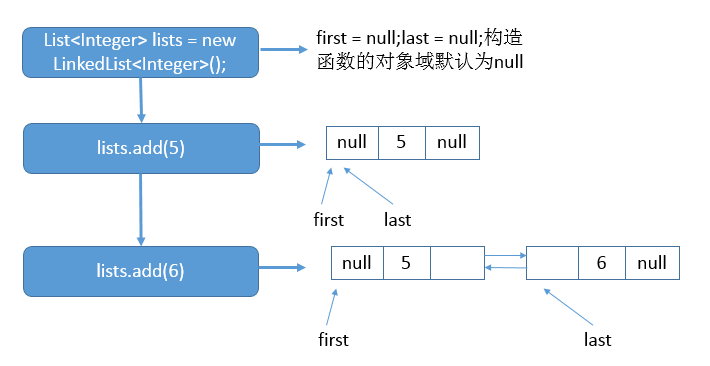
/** * 添加一个元素,默认添加到末尾作为最后一个元素 * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ @Override publicbooleanadd(E e){ linkLast(e); returntrue; }
/** * 从指定的位置插入指定集合的所有元素 * - 如果当前位置有元素存在,将该位置的元素移动到右边 * - 新的元素按照指定集合的迭代器顺序放置 * @param index 插入第一个元素的索引 * @param c collection containing elements to be added to this list * @return {@code true} if this list changed as a result of the call * @throws IndexOutOfBoundsException {@inheritDoc} * @throws NullPointerException if the specified collection is null */ @Override publicbooleanaddAll(int index, Collection<? extends E> c){ // 检查索引是否正确 (0<=index<=size) checkPositionIndex(index); // 得到元素数组 Object[] a = c.toArray(); // 新添加的元素个数 int numNew = a.length; // 若没有元素添加则直接返回false if (numNew == 0) { returnfalse; } // 记录要插入的左右节点信息 Node<E> pred, succ; /* * 如果插入位置为链表末尾 * - 让当前元素前一节点链接原有的尾节点,后一节点链接null * 否则查找出指定位置的节点,在这节点之前链接上元素 * - 前一节点为旧节点的前一节点,后一节点为旧节点 */ if (index == size) { succ = null; pred = last; } else { succ = node(index); pred = succ.prev; }
// 遍历数组 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; // 生成新节点元素 Node<E> newNode = new Node<>(pred, e, null); // 插入位置的前一节点为null,新节点设置为首节点 // 插入位置的前一节点不为null,前一节点的下一节点设置为新节点 if (pred == null) { first = newNode; } else { pred.next = newNode; } // pred设置为新节点,即插入位置后移 pred = newNode; }
/** * 删除第一个元素并返回删除的元素 * @return the first element from this list * @throws NoSuchElementException if this list is empty */ @Override public E removeFirst(){ // 获取到首节点,判断首节点为空则抛出异常 final Node<E> f = first; if (f == null) { thrownew NoSuchElementException(); } return unlinkFirst(f); } /** * 内部方法:删除首节点并返回删除的前首节点的值 */ private E unlinkFirst(Node<E> f){ // assert f == first && f != null; // 获取到首节点的值 final E element = f.item; // 得到下一个节点 final Node<E> next = f.next; // 便于垃圾回收清理 f.item = null; f.next = null; // help GC // 下一节点设置为首节点 first = next; // 如果不存在下一个节点:则首尾都为null(空表) // 如果存在下一节点:它的向前指向为null, if (next == null) { last = null; } else { next.prev = null; } size--; modCount++; return element; }
/** * 删除最后一个元素并返回删除的值 * @return the last element from this list * @throws NoSuchElementException if this list is empty */ @Override public E removeLast(){ // 获取尾节点,如果为空则抛出异常 final Node<E> l = last; if (l == null) { thrownew NoSuchElementException(); } return unlinkLast(l); } /** * 内部方法:删除尾节点并返回删除的前尾节点的值 */ private E unlinkLast(Node<E> l){ // assert l == last && l != null; // 获取尾节点的值 final E element = l.item; // 得出此尾节点的前一节点 final Node<E> prev = l.prev; // 清空尾节点的值和 前一节点(隔断/孤立尾节点) 便于垃圾回收清理 l.item = null; l.prev = null; // help GC // 前一节点设置为尾节点 last = prev; // 如果不存在前一个节点:则首尾都为null(空表) // 如果存在前一个节点:则它的向后指向为null if (prev == null) { first = null; } else { prev.next = null; } size--; modCount++; return element; }
/** * 出队(从前端) * - 如果不存在会抛出异常而不是返回null,存在的话会返回值并移除这个元素(节点) * @return the head of this list * @throws NoSuchElementException if this list is empty */ @Override public E remove(){ return removeFirst(); } /** * 删除列表指定位置的元素 * - 向左移动剩余子元素(对应索引减1) * - 返回列表上被移除的值 * @param index 被移除元素的索引 * @return 指定位置之前的元素 * @throws IndexOutOfBoundsException {@inheritDoc} */ @Override public E remove(int index){ checkElementIndex(index); return unlink(node(index)); } /** * 删除指定节点并返回被删除的元素值 */ E unlink(Node<E> x){ // assert x != null; // 获取当前值和前后节点 final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev;
// 方便gc回收,当前的值置为null x.item = null; size--; modCount++; return element; } /** * 删除指定元素 * - 从first节点开始第一个出现的元素 * - 如果列表中不包含此元素,就不改变 * @param o element to be removed from this list, if present * @return {@code true} if this list contained the specified element */ @Override publicbooleanremove(Object o){ if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); returntrue; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
/** * 清空表:方便gc回收 */ @Override publicvoidclear(){ // Clearing all of the links between nodes is "unnecessary", but: // - helps a generational GC if the discarded nodes inhabit // more than one generation // - is sure to free memory even if there is a reachable Iterator for (Node<E> x = first; x != null; ) { Node<E> next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } first = last = null; size = 0; modCount++; }
3.修改元素
LinkedList提供了set(int index, E element)方法来修改指定索引上的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/** * 用指定位置的元素替换指定位置的元素 * @param index 代替指定位置的元素 * @param element 指定位置被存储的元素 * @return 指定位置之前的元素值 * @throws IndexOutOfBoundsException {@inheritDoc} */ @Override public E set(int index, E element){ checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; }
/** * 获取第一个元素 * @return the first element in this list * @throws NoSuchElementException if this list is empty */ @Override public E getFirst(){ // 获取到首节点,判断首节点为空则抛出异常 final Node<E> f = first; if (f == null) { thrownew NoSuchElementException(); } return f.item; }
4.2getLast
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/** * 获取最后一个元素 * @return the last element in this list * @throws NoSuchElementException if this list is empty */ @Override public E getLast(){ // 获取尾节点,如果为空则抛出异常 final Node<E> l = last; if (l == null) { thrownew NoSuchElementException(); } return l.item; }
4.3get
1 2 3 4 5 6 7 8 9 10 11 12
/** * 获取指定索引的节点值 * @param index index of the element to return * @return the element at the specified position in this list * @throws IndexOutOfBoundsException {@inheritDoc} */ @Override public E get(int index){ // 检查元素索引:0<=index<=size checkElementIndex(index); return node(index).item; }
4.4contains
1 2 3 4 5 6 7 8 9
/** * 检查是否包含某个元素 * @param o element whose presence in this list is to be tested * @return {@code true} if this list contains the specified element */ @Override publicbooleancontains(Object o){ return indexOf(o) != -1; }
/** * 获取指定元素第一次出现的索引,不存在就返回-1 * - 不能二分查找了,所以通常根据索引获得元素的速度比下方通过元素获得索引的速度快 * @param o 待索引的元素 * @return */ @Override publicintindexOf(Object o){ int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { return index; } index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { return index; } index++; } } return -1; }
/** * 获取指定元素从last开始第一次出现的索引,不存在就返回-1 * @param o 待索引的元素 * @return */ @Override publicintlastIndexOf(Object o){ int index = size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) { return index; } } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) { return index; } } } return -1; }
5.node随机访问函数
由LinkedList的类结构可以看出,LinkedList是AbstractSequentialList的子类.AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element)和remove(int index)这些随机访问的函数,那么LinkedList也实现了这些随机访问的接口.LinkedList具体是如何实现随机访问的?即具体是如何定义index这个参数的?
clone、toArray、toArray(T[] a) 以及支持序列化写入函数writeObject(java.io.ObjectOutputStream s)和读取函数readObject(java.io.ObjectInputStream s) —具体见源码全解析
7.Queue队列操作
Queue操作提供了peek、element、poll、remove、offer这些方法
7.1peek
1 2 3 4 5 6 7 8 9
/** * 出队(从前端)获得第一个元素,不存在返回null,不会删除元素(节点) * @return 头部元素没有则返回null */ @Override public E peek(){ final Node<E> f = first; return (f == null) ? null : f.item; }
7.2element
1 2 3 4 5 6 7 8 9
/** * 出队(从前端)获取第一个元素,若为null抛出异常而不是返回null * @return the head of this list * @throws NoSuchElementException if this list is empty */ @Override public E element(){ return getFirst(); }
7.3poll
1 2 3 4 5 6 7 8 9 10
/** * 出队(从前端) * - 如果不存在返回null,存在的话会返回值并删除这个元素(节点) * @return */ @Override public E poll(){ final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); }
7.4remove
1 2 3 4 5 6 7 8 9 10
/** * 出队(从前端) * - 如果不存在会抛出异常而不是返回null,存在的话会返回值并移除这个元素(节点) * @return the head of this list * @throws NoSuchElementException if this list is empty */ @Override public E remove(){ return removeFirst(); }
7.5offer
1 2 3 4 5 6 7 8 9 10
/** * 入队(从后端) * - 始终返回true * @param e the element to add * @return */ @Override publicbooleanoffer(E e){ return add(e); }