ArrayList源码解析 一、ArrayList的定义 1 2 public class ArrayList <E > extends AbstractList <E >implements List <E >, RandomAccess , Cloneable , java .io .Serializable
从ArrayList可以看出它是支持泛型的,它继承自AbstractList,实现List、RandomAccess、Cloneable、java.io.Serializable接口
二、ArrayList属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private static final long serialVersionUID = 8683452581122892189L ;private static final int DEFAULT_CAPACITY = 10 ;private static final Object[] EMPTY_ELEMENTDATA = {};private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};transient Object[] elementData;private int size;
1.transient关键字 此处有个关键字需要解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public class UserInfo implements Serializable private static final long serialVersionUID = -3091184167089157794L ; private String name; private transient String psw; public UserInfo (String name, String psw) this .name = name; this .psw = psw; } @Override public String toString () return "UserInfo{" + "name='" + name + '\'' + ", psw='" + psw + '\'' + '}' ; } } public class TestTransient public static void main (String[] args) UserInfo userInfo = new UserInfo("张三" , "123456" ); System.out.println(userInfo); try { ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("UserInfo.out" )); oos.writeObject(userInfo); oos.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } try { ObjectInputStream ois = new ObjectInputStream(new FileInputStream("UserInfo.out" )); UserInfo userInfo1 = (UserInfo) ois.readObject(); System.out.println(userInfo1.toString()); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }
三、ArrayList构造函数 ArrayList提供了三个构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public ArrayList (int initialCapacity) if (initialCapacity > 0 ) { this .elementData = new Object[initialCapacity]; } else if (initialCapacity == 0 ) { this .elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity); } } public ArrayList () this .elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; } public ArrayList (Collection<? extends E> c) elementData = c.toArray(); if ((size = elementData.length) != 0 ) { if (elementData.getClass() != Object[].class ) { elementData = Arrays.copyOf(elementData, size, Object[].class ) ; } } else { this .elementData = EMPTY_ELEMENTDATA; } }
1.Arrays.copyOf方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { T[] copy = ((Object)newType == (Object)Object[].class ) ? (T[]) new Object[newLength] : (T[]) Array.newInstance(newType.getComponentType(), newLength); System.arraycopy(original, 0 , copy, 0 , Math.min(original.length, newLength)); return copy; } public static int [] copyOf(int [] original, int newLength) { int [] copy = new int [newLength]; System.arraycopy(original, 0 , copy, 0 , Math.min(original.length, newLength)); return copy; }
观察源代码发现copyOf(),在其内部创建了一个新的数组,然后调用arrayCopy()产生新的数组对象返回;总结如下:
copyOf()实现用的是arrayCopy()
arrayCopy()需要目标数组,对两个数组的内容进行可能不完全的合并操作
copyOf()在内部新建一个数组,是用arrayCopy()将oldArray内容复制到newArray中去,并且长度为newLength,返回newArray
2. System.arraycopy() 1 2 3 4 5 6 7 8 public static native void arraycopy (Object src, int srcPos,Object dest, int destPos,int length)
该方法用了native关键字,调用的是C++编写的底层函数,即JDK中的底层函数在实际使用中,如果我们能对所需的ArrayList的大小进行判断 ,有两个好处:
节省内存空间(我们只需放置两个元素到数组—new ArrayList(2))
避免数组扩容引起效率下降(我们只需要放置大约37个元素到数组,new ArrayList(40))
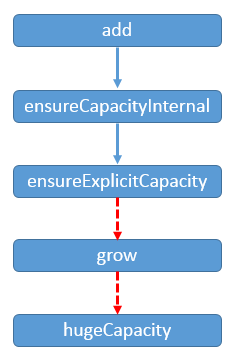
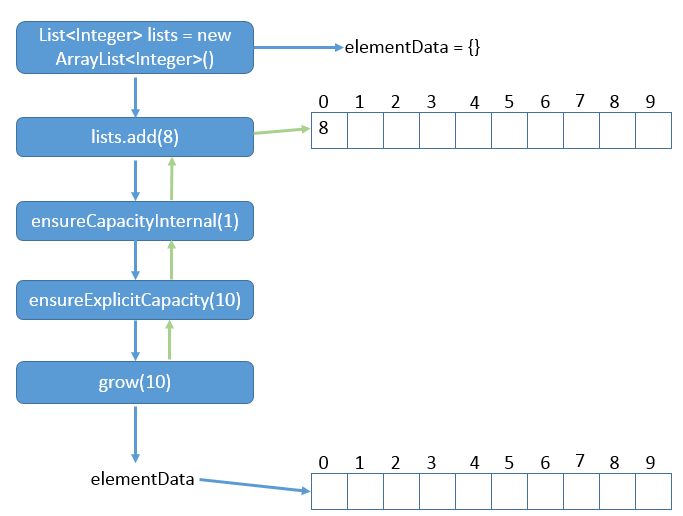
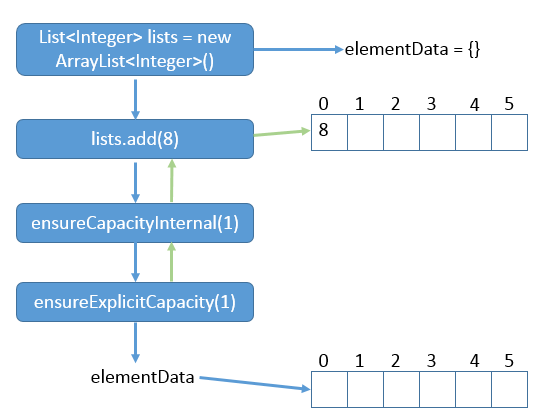
四、ArrayList容量处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 public void trimToSize () modCount++; if (size < elementData.length) { elementData = (size == 0 ) ? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size); } } public void ensureCapacity (int minCapacity) int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) ? 0 : DEFAULT_CAPACITY; if (minCapacity > minExpand) { ensureExplicitCapacity(minCapacity); } } private void ensureCapacityInternal (int minCapacity) if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); } private void ensureExplicitCapacity (int minCapacity) modCount++; if (minCapacity - elementData.length > 0 ) { grow(minCapacity); } } private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 ;private void grow (int minCapacity) int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1 ); if (newCapacity - minCapacity < 0 ) { newCapacity = minCapacity; } if (newCapacity - MAX_ARRAY_SIZE > 0 ) { newCapacity = hugeCapacity(minCapacity); } elementData = Arrays.copyOf(elementData, newCapacity); } private static int hugeCapacity (int minCapacity) if (minCapacity < 0 ) throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
1.modCount解析 首先modCount是从类java.util.AbstractList继承的字段,这个字段主要是为了防止在多线程操作的情况下,List发生结构性的变化https://www.zhihu.com/question/24086463/answer/64717159
五、核心函数分析 1.indexOf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Override public int indexOf (Object o) if (o == null ) { for (int i = 0 ; i < size; i++) { if (elementData[i] == null ) { return i; } } } else { for (int i = 0 ; i < size; i++) { if (o.equals(elementData[i])) { return i; } } } return -1 ; }
2.lastIndexOf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Override public int lastIndexOf (Object o) if (o == null ) { for (int i = size-1 ; i >= 0 ; i--) { if (elementData[i] == null ) { return i; } } } else { for (int i = size-1 ; i >= 0 ; i--) { if (o.equals(elementData[i])) { return i; } } } return -1 ; }
3.clone 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Override public Object clone () try { ArrayList<?> v = (ArrayList<?>) super .clone(); v.elementData = Arrays.copyOf(elementData, size); v.modCount = 0 ; return v; } catch (CloneNotSupportedException e) { throw new InternalError(e); } }
4.toArray 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Override public Object[] toArray() { return Arrays.copyOf(elementData, size); } @Override @SuppressWarnings ("unchecked" )public <T> T[] toArray(T[] a) { if (a.length < size) { return (T[]) Arrays.copyOf(elementData, size, a.getClass()); } System.arraycopy(elementData, 0 , a, 0 , size); if (a.length > size) { a[size] = null ; } return a; }
5.add方法(重点) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 @Override public boolean add (E e) ensureCapacityInternal(size + 1 ); elementData[size++] = e; return true ; } @Override public void add (int index, E element) rangeCheckForAdd(index); ensureCapacityInternal(size + 1 ); System.arraycopy(elementData, index, elementData, index + 1 , size - index); elementData[index] = element; size++; }
说明:正常情况下会扩容1.5倍,特殊情况下
指定为空数组时为0
新扩展数组大小已经达到了最大值则只取最大值
5.1无参构造时add运行 1 2 List<Integer> lists = new ArrayList<Integer>(); lists.add(8 );
说明:初始化list大小为0,调用ArrayList()型构造函数,那么在调用list.add()方法时是怎样的?
5.2有参构造add运行 1 2 List<Integer> lists = new ArrayList<Integer>(6 ); lists.add(8 );
6.trimToSize() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public void trimToSize () modCount++; if (size < elementData.length) { elementData = (size == 0 ) ? EMPTY_ELEMENTDATA : Arrays.copyOf(elementData, size); } }
将ArrayList容量设置为当前size大小,首先需要明确一个概念,ArrayList的size就是ArrayList的元素个数,length是ArrayList申请的内容空间长度.ArrayList每次都会预申请多一点空间,以便添加元素的时候不需要每次都进行扩容操作,例如我们的元素个数是10个,它申请的内存空间必定会大于10,即length>size,而这个方法就是把ArrayList的内存空间设置为size,去除没有用到的null值空间.这也就是我们为什么每次在获取数据长度是都是调用list.size()而不是list.length()
7.removeAll和retainAll(重点) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Override public boolean removeAll (Collection<?> c) Objects.requireNonNull(c); return batchRemove(c, false ); } @Override public boolean retainAll (Collection<?> c) Objects.requireNonNull(c); return batchRemove(c, true ); }
在实际开发中removeAll这个动作很耗时,因为在bacthRemove需要循环原来的list,此时还会调用contains方法,而在contains方法中的indexOf方法又会循环一次,即removeAll两层for循环,复杂度O(m*n),所以在操作比较大的ArrayList时这种方法绝对不可取,可以采用下面的方式
1 2 3 4 5 6 7 8 9 10 11 12 private List<Integer> removeAll (List<Integer> src, List<Integer> target) LinkedList<Integer> result = new LinkedList<>(src); HashSet<Integer> targetHash = new HashSet<>(target); Iterator<Integer> iter = result.iterator(); while (iter.hasNext()){ if (targetHash.contains(iter.next())){ iter.remove(); } } return result; }
7.1比较两种removeAll
外层循环
内层数据比较
7.2Hash表简单介绍 Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录关键字进行比较来查找,这个源于Hash表设计的特殊性,它采用函数映射思想将记录的存储位置与记录的关键字关联起来,从而能够快速进行查找,可以简单理解为,以空间换时间,牺牲空间复杂度来换取时间复杂度
8.遍历ArrayList的对象iterator 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Override public ListIterator<E> listIterator (int index) if (index < 0 || index > size) { throw new IndexOutOfBoundsException("Index: " + index); } return new ListItr(index); } @Override public ListIterator<E> listIterator () return new ListItr(0 ); } @Override public Iterator<E> iterator () return new Itr(); }
iterator方法是Abstract中实现的,该方法返回AbstractList一个内部类Itr对象
9.subList 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Override public List<E> subList (int fromIndex, int toIndex) subListRangeCheck(fromIndex, toIndex, size); return new ArrayList.SubList(this , 0 , fromIndex, toIndex); }
六、ArrayList的内部类 1 2 3 4 private class Itr implements Iterator <E >private class ListItr extends Itr implements ListIterator <E >private class SubList extends AbstractList <E > implements RandomAccess static final class ArrayListSpliterator <E > implements Spliterator <E >
1.Itr Itr实现了Iterator接口,同时重写了里面的hasNext()、next()、remove()、forEachRemaining等方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 private class Itr implements Iterator <E > int cursor; int lastRet = -1 ; int expectedModCount = modCount; @Override public boolean hasNext () return cursor != size; } @Override @SuppressWarnings ("unchecked" ) public E next () checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1 ; return (E) elementData[lastRet = i]; } @Override public void remove () if (lastRet < 0 ) { throw new IllegalStateException(); } checkForComodification(); try { ArrayList.this .remove(lastRet); cursor = lastRet; lastRet = -1 ; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } } @Override @SuppressWarnings ("unchecked" ) public void forEachRemaining (Consumer<? super E> consumer) Objects.requireNonNull(consumer); final int size = ArrayList.this .size; int i = cursor; if (i >= size) { return ; } final Object[] elementData = ArrayList.this .elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } while (i != size && modCount == expectedModCount) { consumer.accept((E) elementData[i++]); } cursor = i; lastRet = i - 1 ; checkForComodification(); } final void checkForComodification () if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } } }
2.ListItr 继承Itr,实现了ListIterator接口;
ListIterator有add()方法,可以向List中添加对象,而Iterator不能
ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历.但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历.Iterator就不可以
ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现.Iterator没有此功能
都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现.Iterator仅能遍历,不能修改.因为ListIterator的这些功能,可以实现对LinkedList等List数据结构的操作
3.SubList 继承AbstractList,实现了RandomAccess接口,类内部实现了对子序列的增删改查等方法,同时也充分利用了内部类的优点,就是共享ArrayList的全局变量,例如检查器变量modCount,数组elementData等,所以SubList进行的增删改查操作都是对ArrayList的数组进行的,并没有创建新的数组
4.ArrayListSpliterator 七、ArrayList源码全解析 八、ArrayList总结
ArrayList基于数组实现,其内存储元素的数组为elementData,elementData声明为transient Object[] elementData;
ArrayList中EMPTY_ELEMENTDATA和DEFAULTCAPACITY_EMPTY_ELEMENTDATA的使用—这两个常量数组的使用场景不同,前者是用户通过ArrayList(int initialCapacity)该构造方法直接指定初试容量为0时,后者是用户直接使用无参构造创建ArrayList时
ArrayList默认容量为10,调用无参构造新建一个ArrayList时,其elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA,当第一次使用add()添加元素时,ArrayList的容量会为10
ArrayList的toArray()方法和subList()方法,在源数据和子数据之间的区别
toArray():对该方法返回的数组,进行操作(增删改查)都不会影响源数据(ArrayList中的elementData).二者是不会相互影响的
九、c.toArray的官方bug public Object[] toArray()返回的类型不一定就是Object[], 其类型取决于其返回的实际类型
1.代码分析 1.1创建类 1 2 3 public class Father public class Son extends Father
1.2测试1 1 2 3 4 5 6 7 8 9 10 @Test public void test1 () Son[] sons = {new Son(), new Son()}; System.out.println(sons.getClass()); Father[] fathers = sons; System.out.println(fathers.getClass()); fathers[0 ] = new Father(); }
对于fathers[0] = new Father(); 这句话,为什么会报错?
1.3测试2 新建一个MyList,该类继承ArrayList
1 2 3 4 5 6 public class MyList <E > extends ArrayList <E > @Override public String[] toArray() { return new String[]{"1" , "2" , "3" }; } }
测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void test2 () List<String> ss = new LinkedList<>(); ss.add("123" ); Object[] objs = ss.toArray(); objs[0 ] = new Object(); ss = new MyList<>(); objs = ss.toArray(); System.out.println(objs.getClass()); objs[0 ] = new Object(); }
当我们调用List的toArray()时,我们实际调用的是其具体实现类MyList中重写的String[] toArray()方法.因此数组并不是Object[]而是String[],而向下转型是不安全的,因此会抛出异常
抽象类(接口)其具体类型,取决于实例化时所采用的导出类的类型
子类实现和父类同名方法,当返回值不一致时,默认调用的是子类的实现方法;如MyList中的String[] toArray